

USE CASE
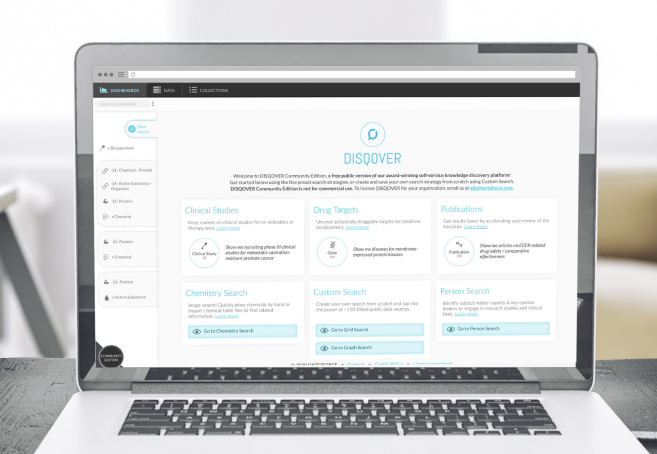

ONTOFORCE enables life science companies to unlock hidden insights from data.
With DISQOVER, built on knowledge graph technology, we support life sciences and pharmaceutical companies with innovative data management and visualization.
![]()
![]()




