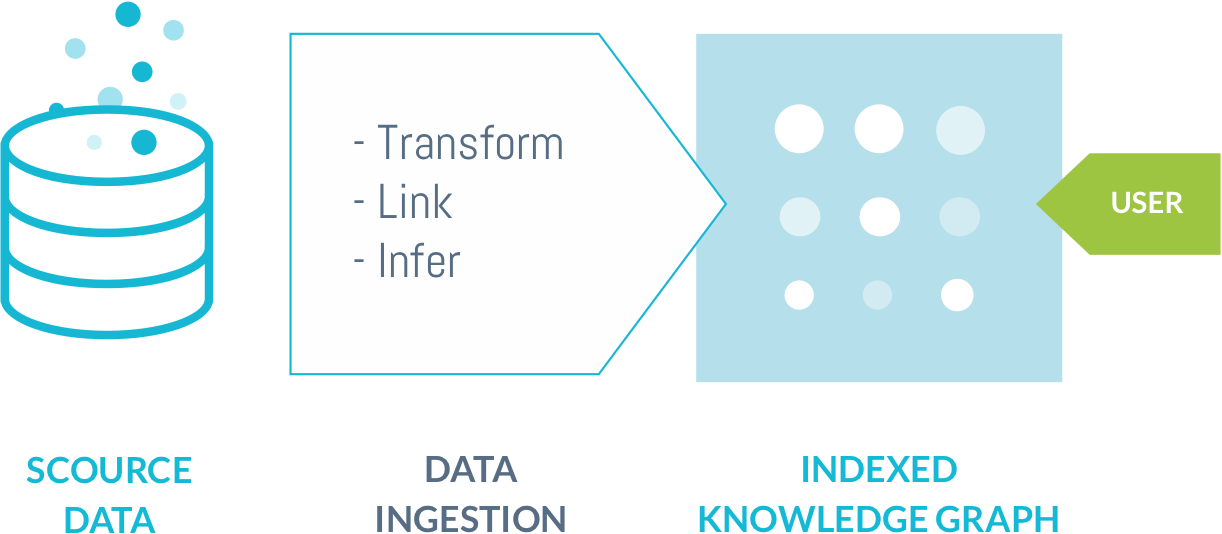
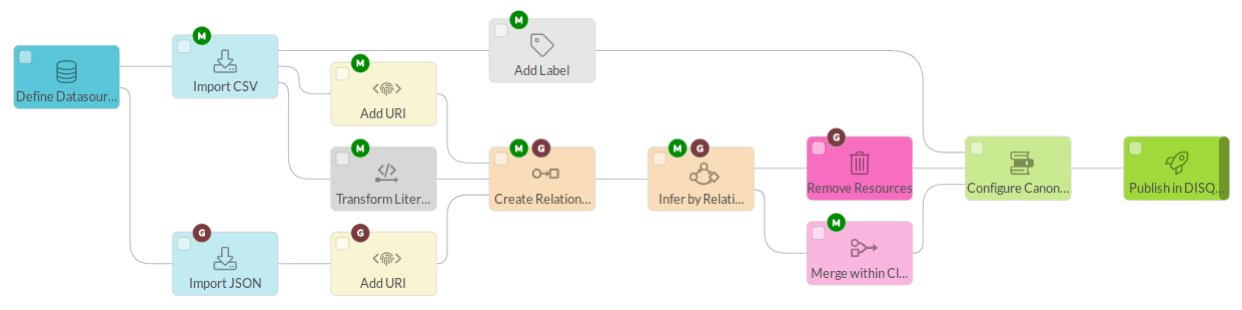
When you are configuring the integration of your source data in DISQOVER, you can manage the data-ingestion process by building a visual pipeline, using a wide range of powerful reusable components. There is no need to write extensive code, which means that, compared to a conventional approach relying on RDF SPARQL, fewer specialized skills are needed and development time is reduced, while retaining the same level of power and flexibility.
A visual pipeline makes it easier to communicate the choices made during data integration, resulting in increased transparency and auditability, and fewer chance of error. Stakeholders with only basic IT knowledge can understand, review, challenge, and contribute to the data integration process.